Historical & Mathematical Foundations
Artificial neural networks, which power much of today’s AI, trace their origins to one of the first machine learning models: the perceptron. Developed by Frank Rosenblatt in 1958 at the Cornell Aeronautical Laboratory, the perceptron was designed to recognize patterns, learn from examples, and improve its performance over time, a revolutionary idea for the era of early computing. Rosenblatt envisioned machines that could learn in ways similar to the human brain, marking a significant step toward intelligent systems.
Origins of Perceptrons
The perceptron was directly inspired by the structure and function of biological neurons. Rosenblatt sought to replicate a simplified version of how the brain processes information: inputs are received, weighted according to importance, summed, and then passed through a decision mechanism to determine the output. This allowed the perceptron to classify visual patterns, such as distinguishing letters or shapes, based on training examples.
Although computational resources were extremely limited in the 1950s, the perceptron demonstrated that machines could, in principle, learn from data, a concept that laid the groundwork for decades of research in neural networks and machine learning. Its development highlighted both the promise and the challenges of creating machines that emulate cognitive processes.
Biological Inspiration
The perceptron takes inspiration from biological neurons, the fundamental units of the brain. In a biological neuron, dendrites collect incoming signals from other neurons, which are then summed in the cell body (soma). If the combined signal is strong enough, it travels down the axon to communicate with other neurons. The connections between neurons, called synapses, can strengthen or weaken over time, influencing how effectively signals are transmitted.
- Dendrites – receive input signals
- Cell body (soma) – sums incoming signals
- Axon – transmits output signals
- Synapses – connections that vary in strength
The image below illustrates these components, showing how the parts of a neuron interact to process and transmit information:
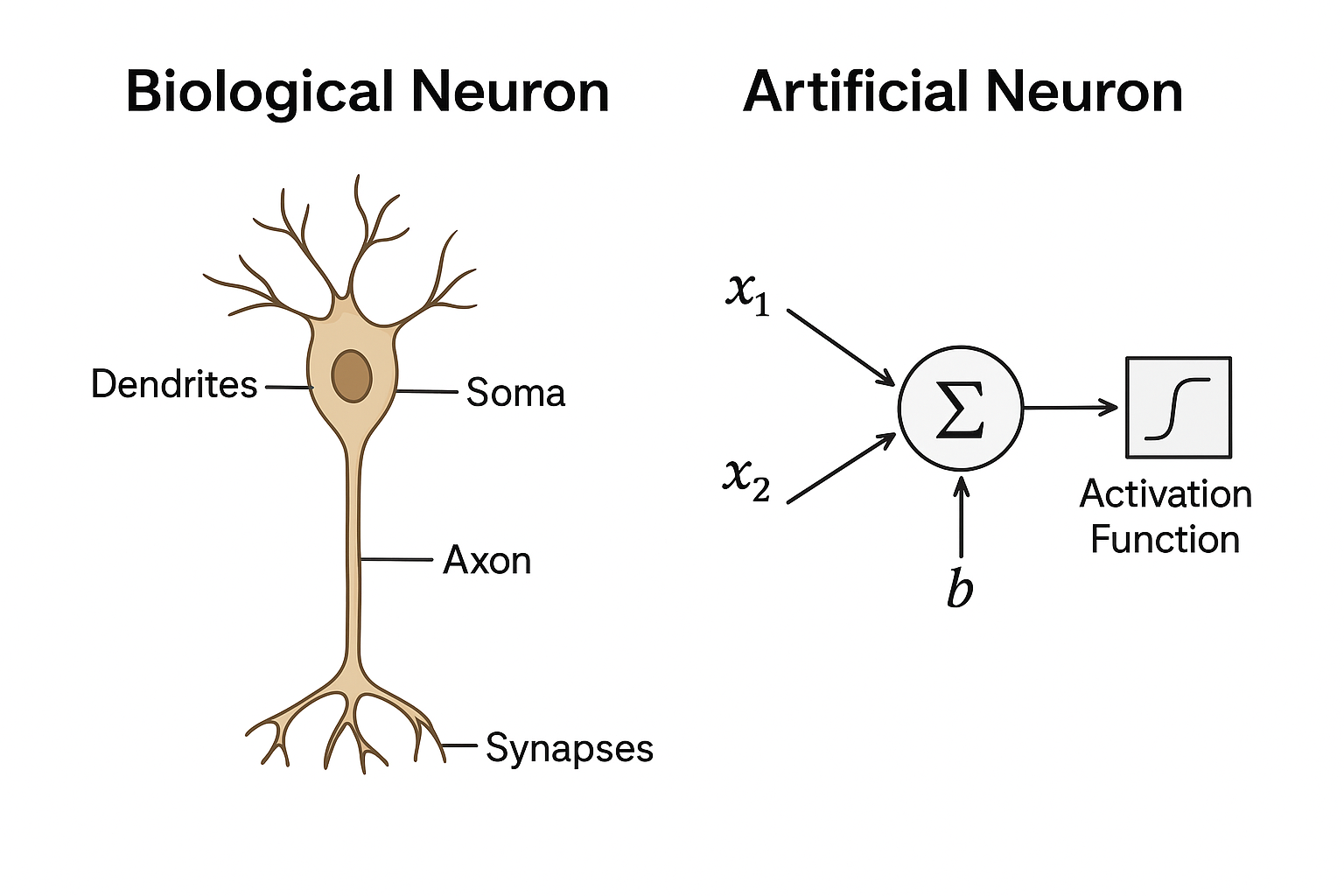
By observing this biological model, we can see how an artificial neuron mimics the same process. Each input is assigned a weight, representing the “strength” of the connection, similar to synaptic strength. These weighted inputs are summed, and the total is passed through an activation function, which determines the neuron’s output. This simple yet powerful model forms the foundation of perceptrons and neural networks.
Linear Threshold Units
A perceptron generates an output using a linear threshold function, which determines whether the neuron “fires” or stays inactive. Mathematically, this can be expressed as:
- y = 1 if (sum(wi * xi) + b) >= 0
- y = 0 if (sum(wi * xi) + b) < 0
Where:
- xi = input signal
- wi = weight applied to each input
- b = bias, which shifts the threshold
In simple terms, the perceptron sums the weighted inputs and adds the bias. If the total exceeds the threshold (0 in this case), the neuron outputs 1; otherwise, it outputs 0. This step function provides a straightforward mechanism for making binary decisions and serves as the foundation for early neural network models.
Perceptron Learning Rule
The perceptron improves its performance by adjusting its weights to reduce errors in its predictions. The learning rule is:
wi = wi + eta * (t - y) * xiWhere:
- t = target output
- y = actual output
In other words, the weights are nudged in the direction that corrects mistakes, allowing the perceptron to gradually “learn” the correct classification. Over multiple examples, this simple adjustment rule enables the network to converge towards accurate predictions.
The XOR Problem
Single-layer perceptrons are effective for simple, linearly separable tasks, but they have a significant limitation: they cannot solve problems where the data is not linearly separable. A classic example is the XOR function:
| X1 | X2 | XOR |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
No single straight line can separate the 1s from the 0s in this dataset. This limitation highlighted the need for multi-layer networks, which can handle non-linear relationships and paved the way for modern neural networks.
Unit Summary
- Origins of Perceptrons: Developed by Frank Rosenblatt in 1958, the perceptron was one of the first machine learning models, designed to recognize patterns and learn from examples. It was inspired by the structure and function of biological neurons.
- Biological Inspiration: Dendrites receive inputs, the cell body (soma) sums them, axons transmit outputs, and synapses modulate connection strength. Artificial neurons mimic this process using weighted inputs and an activation function.
- Linear Threshold Units: A perceptron outputs 1 if the weighted sum of inputs plus bias exceeds a threshold, otherwise outputs 0. This step function enables simple binary decision-making.
- Perceptron Learning Rule: Weights are updated using wi = wi + eta * (t - y) * xi allowing the perceptron to correct errors and gradually improve classification accuracy.
- The XOR Problem: Single-layer perceptrons cannot solve non-linearly separable problems, such as XOR, because no single straight line can separate the outputs. This limitation motivated the development of multi-layer networks to handle complex patterns.