Activation Functions Beyond Step
Activation functions determine how a perceptron or neuron transforms its input into an output. They are not just mathematical functions, they shape learning, define decision boundaries, and enable networks to model complex patterns. Choosing the right activation function affects how efficiently a network trains, how gradients propagate, and whether a network can solve non-linear problems. In this module, we explore activation functions beyond the step function, focusing on sigmoid, tanh, and ReLU, and we show why nonlinear activations are crucial for multi-layer networks.
Comparing Common Activation Functions
Activation functions shape how neurons transform inputs into outputs. The following figure illustrates four common activation functions: step, sigmoid, tanh, and ReLU, showing their output ranges and shapes.
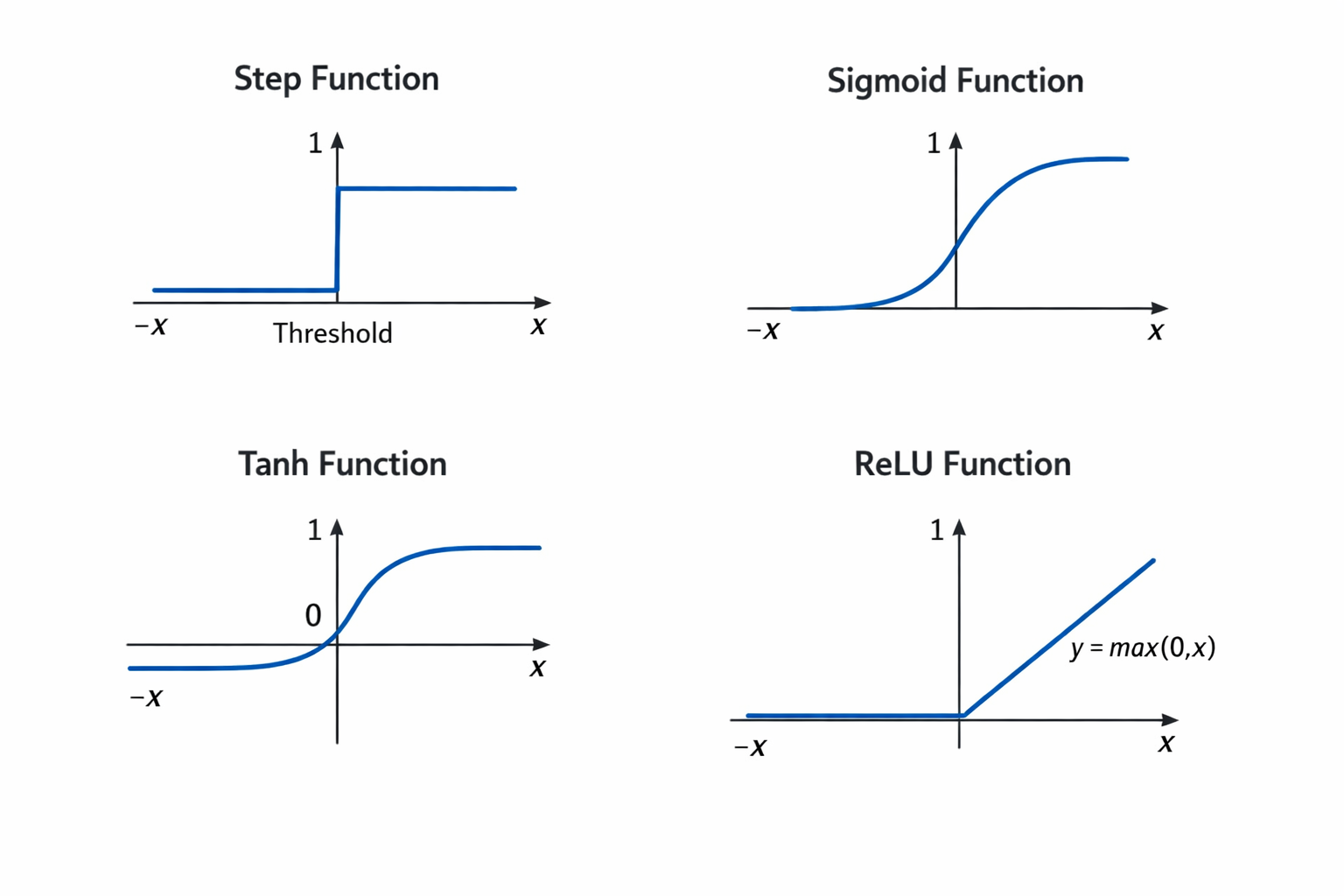
Step Function
This is the simplest form of activation. It outputs 1 if the input exceeds a threshold and 0 otherwise. While conceptually easy to understand, it is non-differentiable. Since gradient-based learning relies on computing derivatives to update weights, the step function effectively blocks learning in multi-layer networks. Its decision boundaries are rigid and linear, suitable only for linearly separable problems.
Sigmoid Function
Improves upon the step function by introducing smoothness. Mathematically, it is expressed as 1 / (1 + e^(-x)). Sigmoid outputs values between 0 and 1, which can be interpreted as probabilities. Its smooth gradient allows backpropagation to work, making it suitable for multi-layer networks. However, sigmoid saturates for large positive or negative inputs, causing gradients to vanish. This slows down learning in deep networks.
Tanh Function
The tanh function given by (e^x - e^(-x)) / (e^x + e^(-x)), maps inputs to the range (-1, 1). Being zero-centered, tanh often leads to faster convergence compared to sigmoid because weight updates are less biased in one direction. Like sigmoid, tanh still suffers from vanishing gradients when inputs are very large or very small.
ReLU (Rectified Linear Unit)
This function is defined as max(0, x). ReLU is computationally efficient and avoids vanishing gradients for positive inputs. Its piecewise-linear behavior allows multi-layer networks to form complex decision surfaces. The main drawback is the “dying ReLU” problem: if a neuron consistently outputs zero, it may stop learning entirely. Despite this, ReLU remains the default activation in most deep networks due to its simplicity and effectiveness.
Differentiability & Smoothness
Differentiability is central to gradient-based learning. Backpropagation computes weight updates by using derivatives of the activation function.
- The step function has a derivative of zero almost everywhere, which blocks backpropagation and prevents learning in deeper networks.
- Sigmoid and tanh are smooth and differentiable across their domains, allowing gradients to propagate and weights to update effectively.
- ReLU is differentiable everywhere except at zero. In practice, sub gradients are used at zero, enabling continued learning.
Smooth, differentiable activations are therefore essential for training multi-layer networks.
Effect on Decision Boundaries
Activation functions also shape the type of decision boundaries a network can learn.
- Step functions create hard, rigid boundaries that can only separate linearly separable data.
- Sigmoid and tanh allow smooth, soft transitions. In single neurons, this produces soft linear boundaries, and in multi-layer networks, it enables the formation of more complex, curved surfaces.
- ReLU produces piecewise-linear boundaries, which when combined across layers, allow the network to approximate highly complex and nonlinear decision surfaces.
Why Step Functions Block Backpropagation
Backpropagation relies on gradients to propagate error signals backward through the network. The derivative of the step function is zero almost everywhere, meaning no gradient flows through the network. Without gradients, weights cannot update and learning stalls. Smooth functions such as sigmoid, tanh, and ReLU provide non-zero derivatives, allowing errors to propagate and weights to adjust.
Transition to Multi-Layer Perceptrons (MLPs)
Single-layer perceptrons are limited to linearly separable problems. Multi-layer networks, however, can solve non-linear problems, thanks to nonlinear activation functions. Hidden layers combine inputs in complex ways, enabling the network to represent intricate mappings from inputs to outputs. This capability underpins the Universal Approximation Theorem, which states that a network with at least one hidden layer and a nonlinear activation function can approximate any continuous function to arbitrary precision. Nonlinear activations are therefore critical for solving problems like XOR or image recognition, which cannot be handled by single-layer perceptrons.
Unit Summary
- Step Function: Outputs 0 or 1 based on a threshold; non-differentiable and blocks gradient-based learning.
- Sigmoid: Smooth, differentiable, outputs in (0,1), interpretable as probabilities; can suffer vanishing gradients for large inputs.
- Tanh: Smooth, differentiable, outputs in (-1,1), zero-centered for faster convergence; still affected by vanishing gradients.
- ReLU: Outputs max(0, x); computationally efficient, avoids vanishing gradients for positive inputs, but can cause “dying” neurons.
- Differentiability: Essential for backpropagation; non-zero derivatives enable weight updates across layers.
- Decision Boundaries: Step creates hard, linear boundaries; sigmoid and tanh produce smooth, soft boundaries; ReLU allows piecewise-linear boundaries that can form complex decision surfaces.
- Nonlinearity in MLPs: Enables multi-layer networks to combine inputs in complex ways, solve non-linear problems like XOR, and approximate any continuous function (Universal Approximation Theorem).